Build a String
Build A String
The build a string question is posed on HackerRank here. For the sake of concise-ness, I won’t repeat the question.
Take a minute to read it.
Are you done yet? Okay, good. Time to get solvin’.
Attempt 1: Dynamic Programming
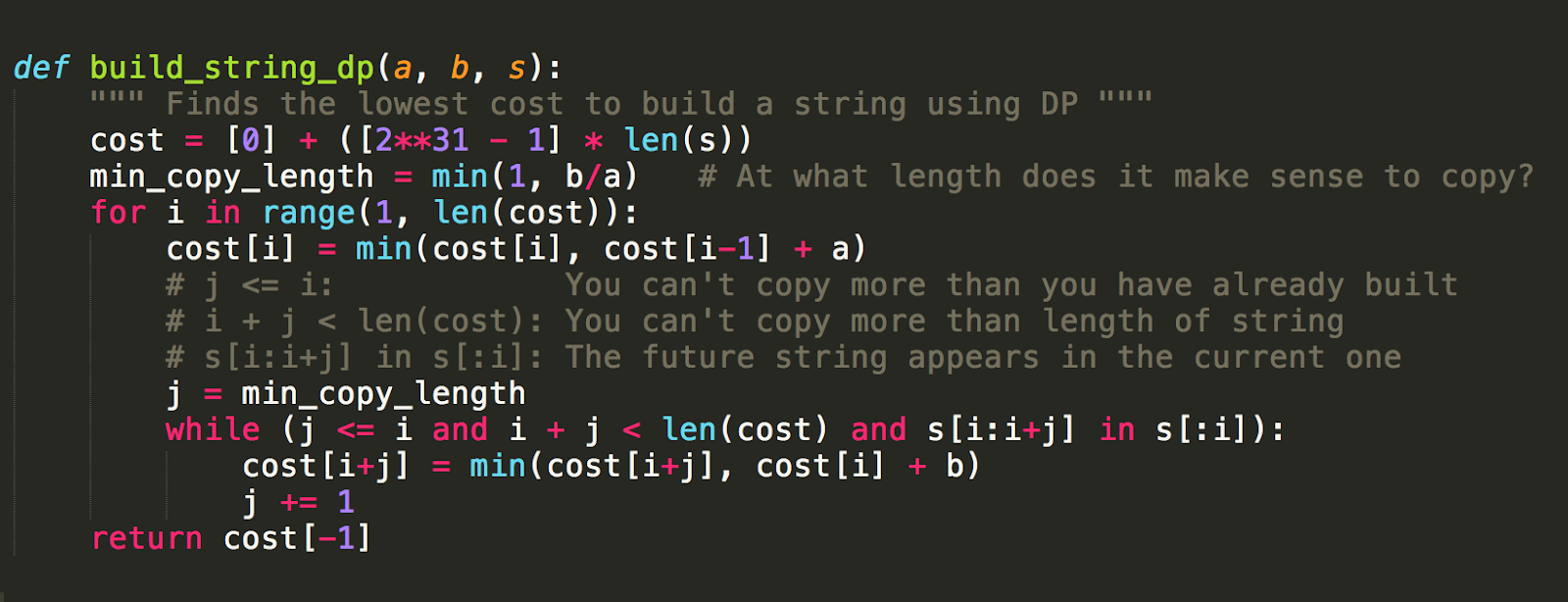
Immediately after reading the problem, my mind goes to a dynamic programming solution. I quickly draft some Python code:
Yes, I use Sublime Text, the world’s easiest and nicest looking text editor. Don’t judge me, vim-lords.
Anyway, this solution is very straightforward. All we do here is keep the lowest costs so far in an array as we build the new string, so we have cached values that we can overwrite in the array.
There are a few minor pruning optimizations I had added in, but they’re not too important. I left comments in the code describing what they are.
This simple, quick and dirty solution is of O(n3) time complexity. It passes the first 10 out of 20 solutions, with the last half timing out. We’re halfway there. (oh oh, living on a prayer!)

In order to optimize the algorithm, we must examine its pain points. One of the major items slowing it down is last condition in the while loop: s[i:i+1], s[i:i+2],... in s[:i].
Let’s tackle that one first.
Attempt 2: DP + Caching Found Substrings
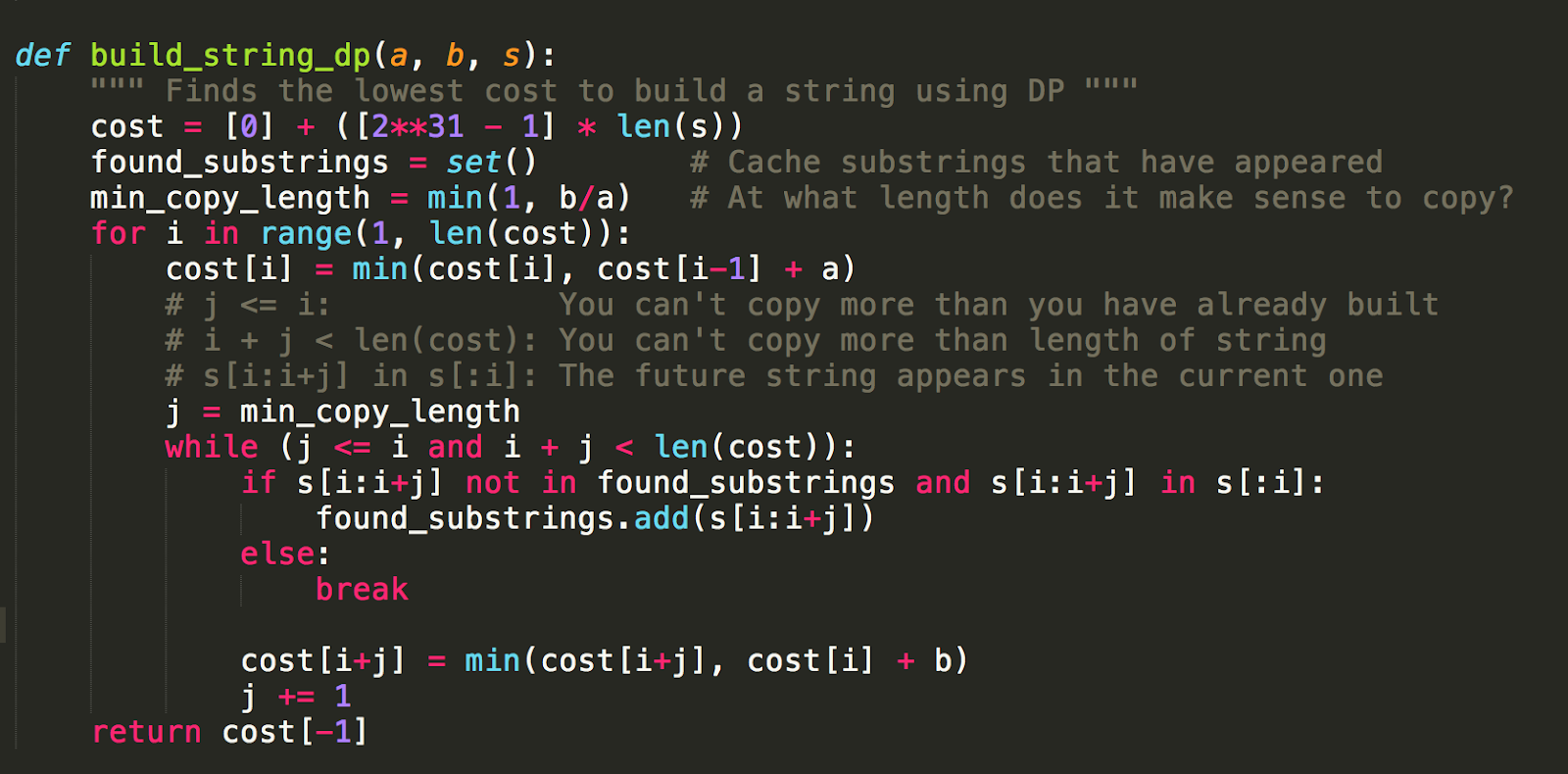
The new code doesn’t change much from the old, except that it now has a found_substrings set that caches repeated substrings. The idea is that we shouldn’t need to compute that expensive operation more than once.
Great in theory, not so great in practice. Unfortunately HackerRank gives a runtime error; likely the set uses too much memory.
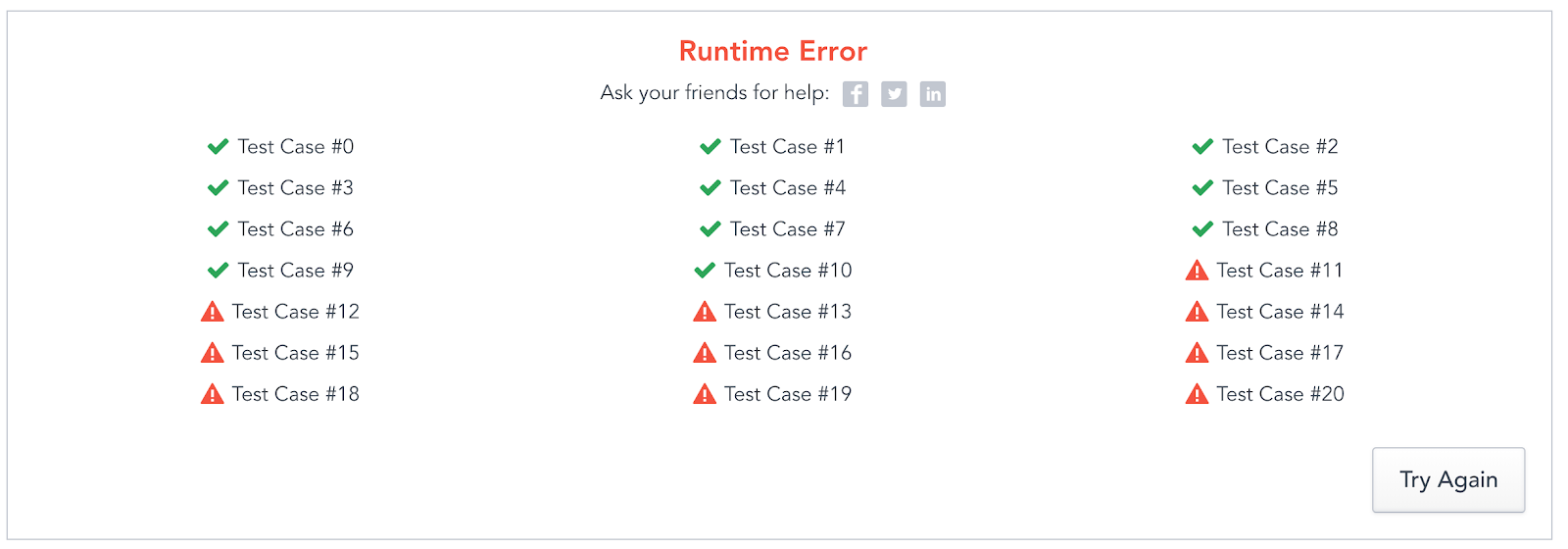
Attempt 3: DP + Caching Found Indices
I tried running this same code again, except now instead of caching the whole string, I cache the pair of indices where the string starts and ends, but run into the same runtime issue as Attempt 2.
Attempt 4: Rabin Karp
Okay, time to pull out the big guns. If a simple solution doesn’t want to work, I guess I’ll have to pull out something a little more advanced. In this case, it was after a few days of googling around and checking stack overflow for inspiration in solving this problem. Finally, I had settled on an optimization of Python’s in using Rabin Karp search.
The naive approach for deciding if one string is a substring of another is to match 1 by 1.
Rabin-Karp introduces another way to match strings: it matches the hash value of the pattern with the hash value of current substring of text, and if the hash values match then only it starts matching individual characters. As the window slides, it only takes O(1) time to compute the new hash, and O(1) time to compare hashes.
Doing a full string comparison would take up to O(m) time every time you slide the window, where m is the length of the substring.
Here goes nothing, having just learned the existence of Rabin-Karp a few minutes prior.
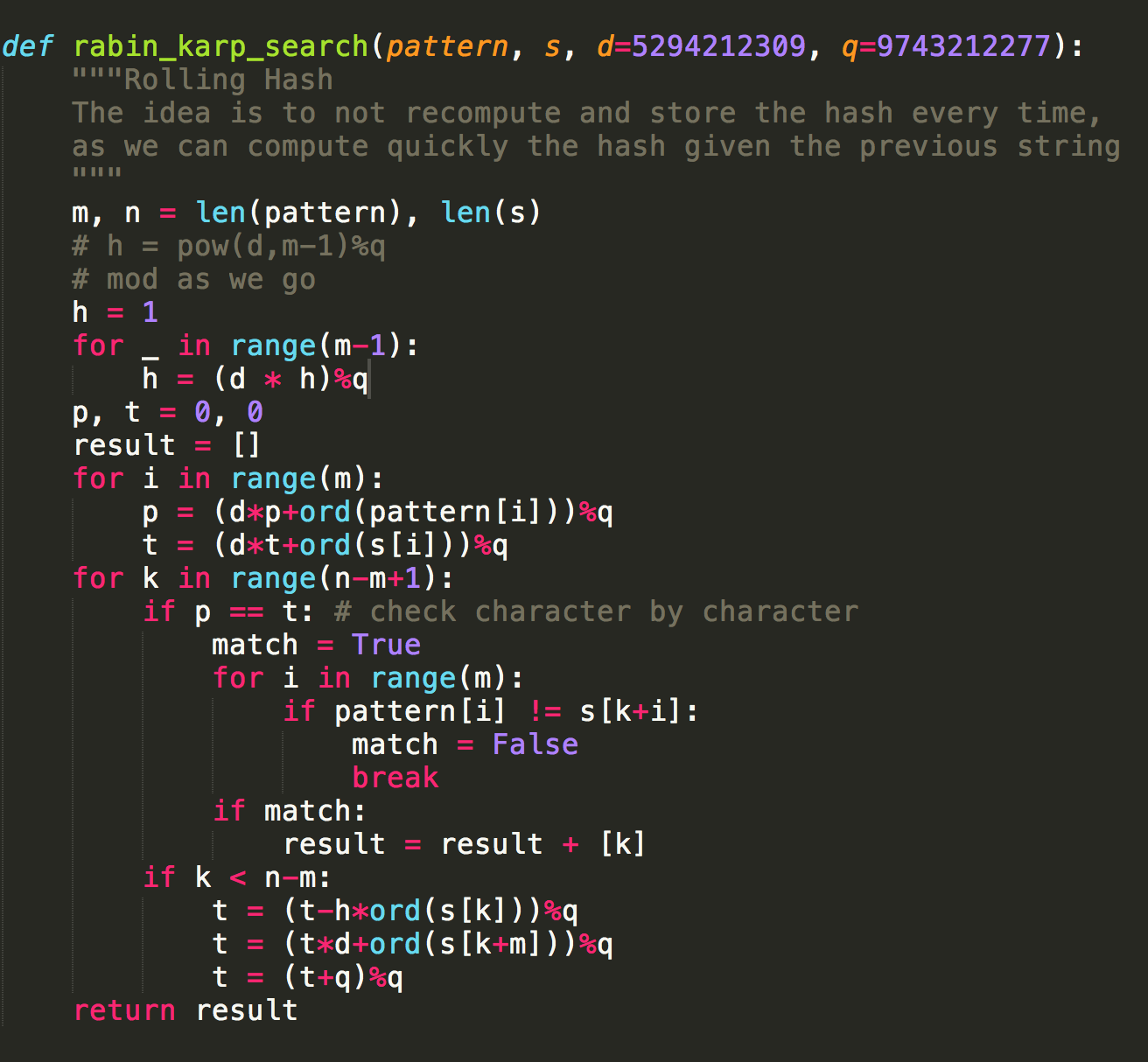
I substitute the Rabin Karp search into our previous attempts’ while loop.

Unfortunately, I have done something truly awful, as Rabin Karp decides to Karp out on me.
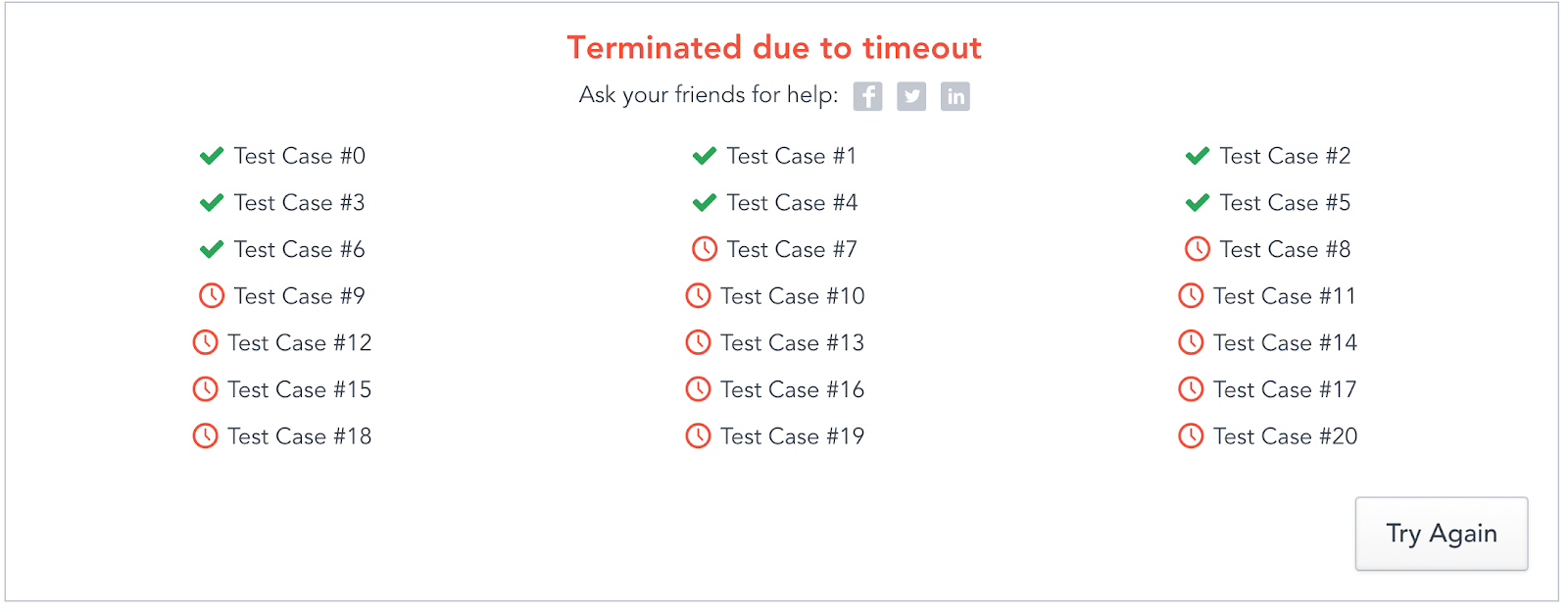
Likely there is a bug, or maybe I failed to implement the algorithm correctly. However, by this point I’m ready to rethink a solution.
Attempt 5: Suffix Arrays
Suffix Arrays is another random topic I found on google a way to quickly index into every occurrence of a substring pattern P within the string S. Basically, it takes O(n log n) time to construct a suffix array that stores an array of all suffixes in a string. You can read more about them here.
Oh man, here we go again. cracks knuckles
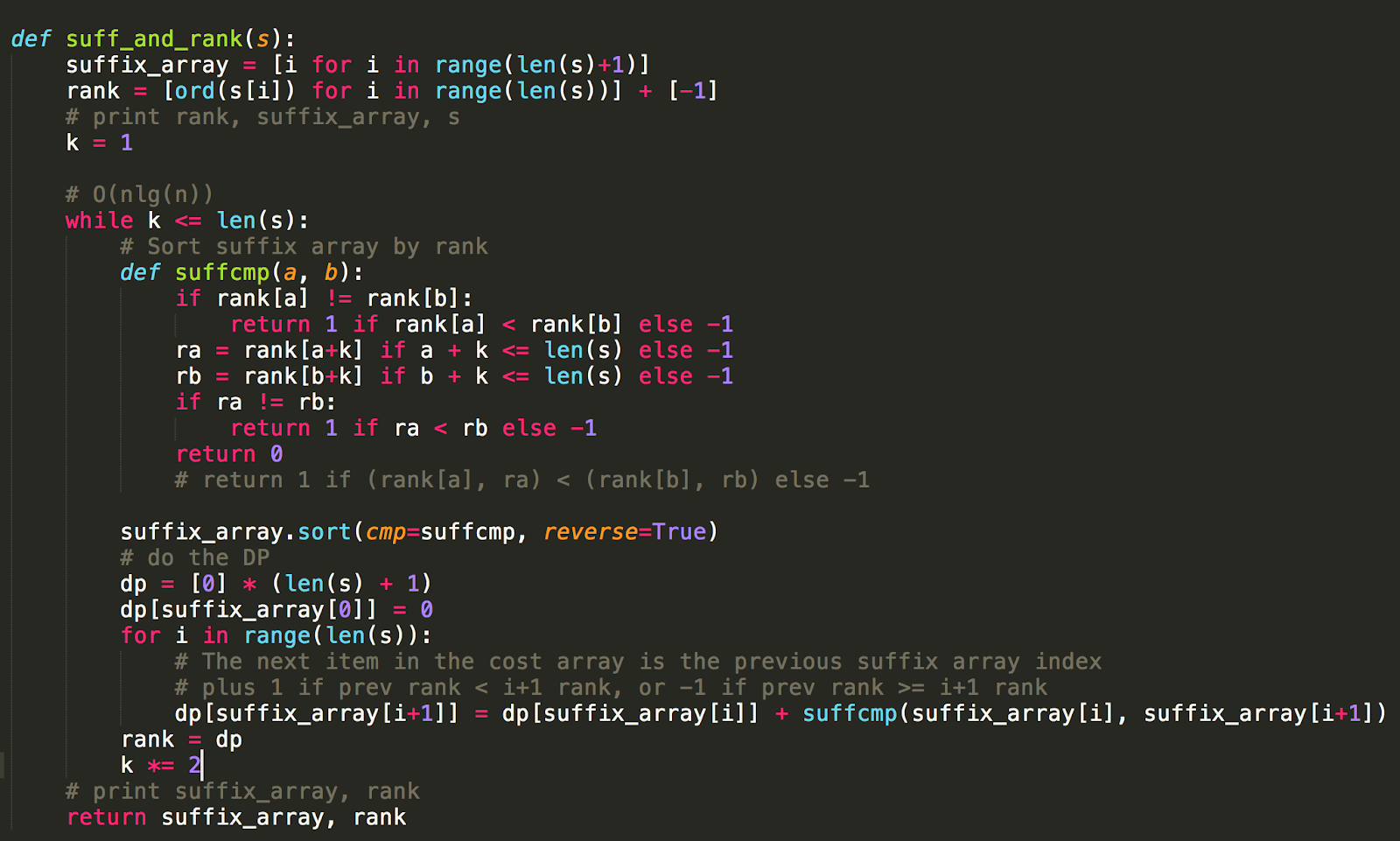
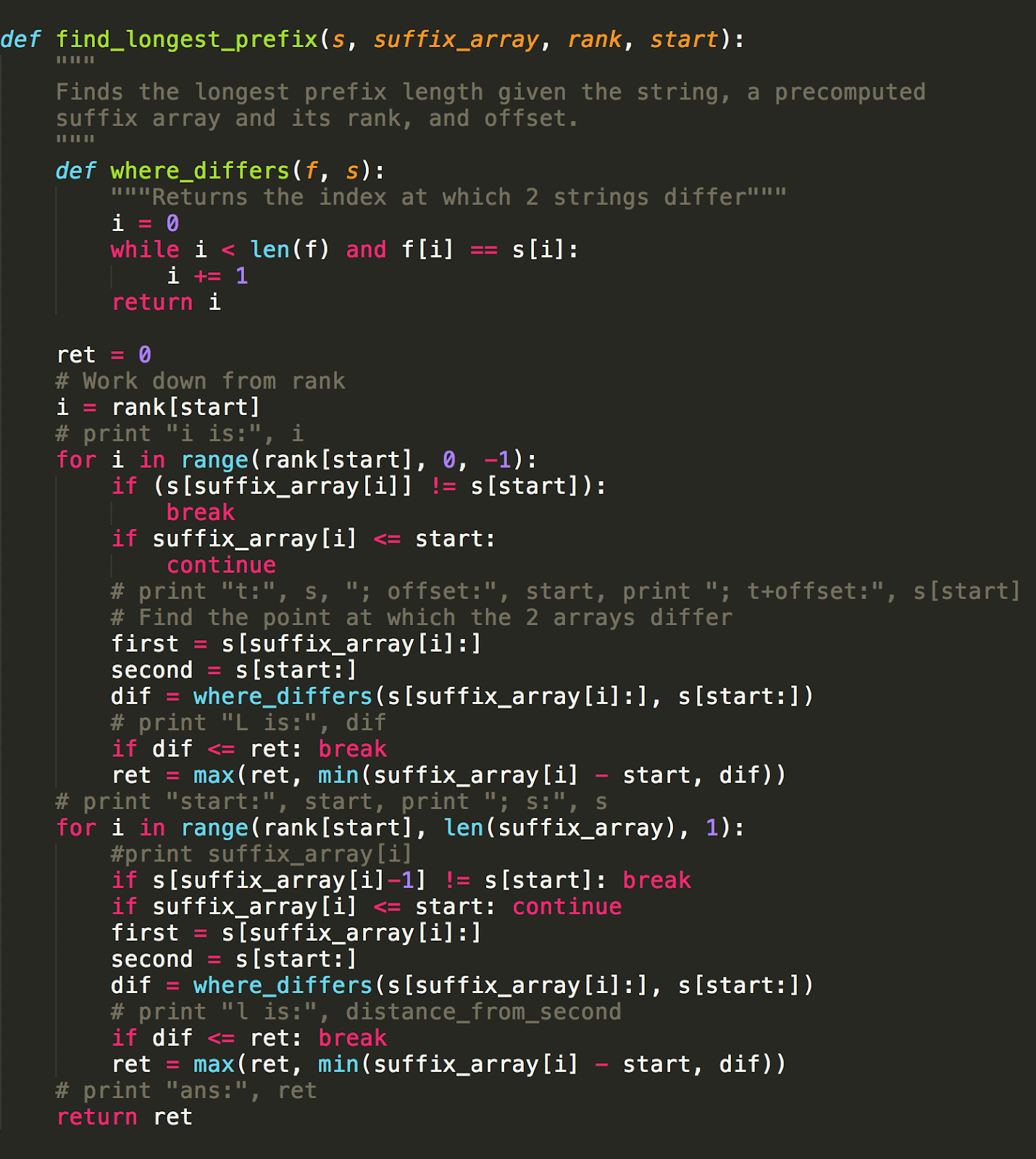
What a doozy to understand and implement… now I can plug and play this algorithm, and get a 20/20 test case pass!
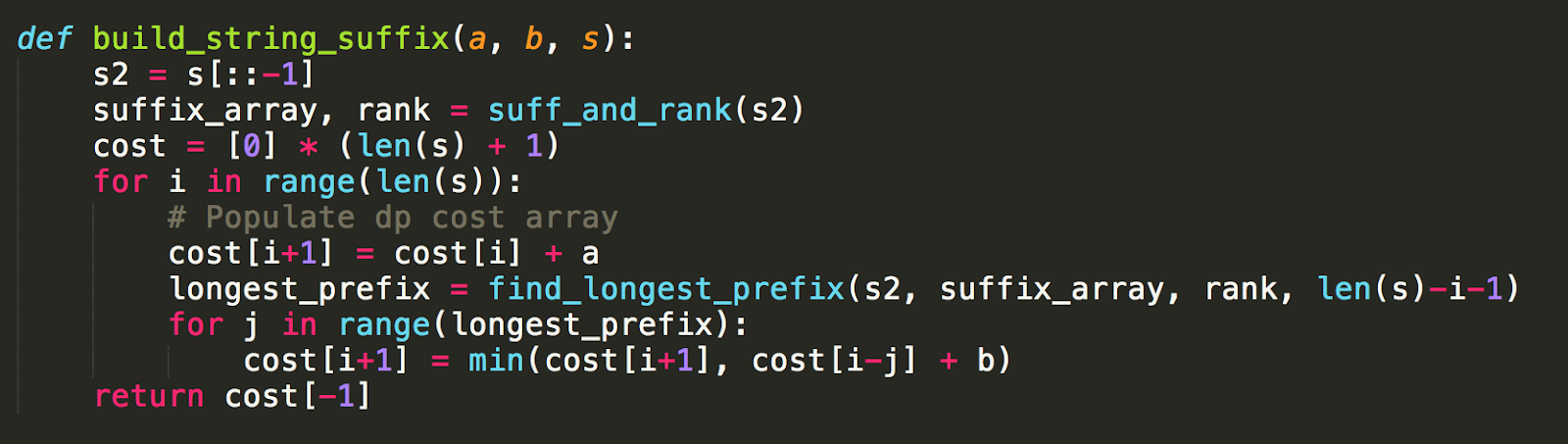
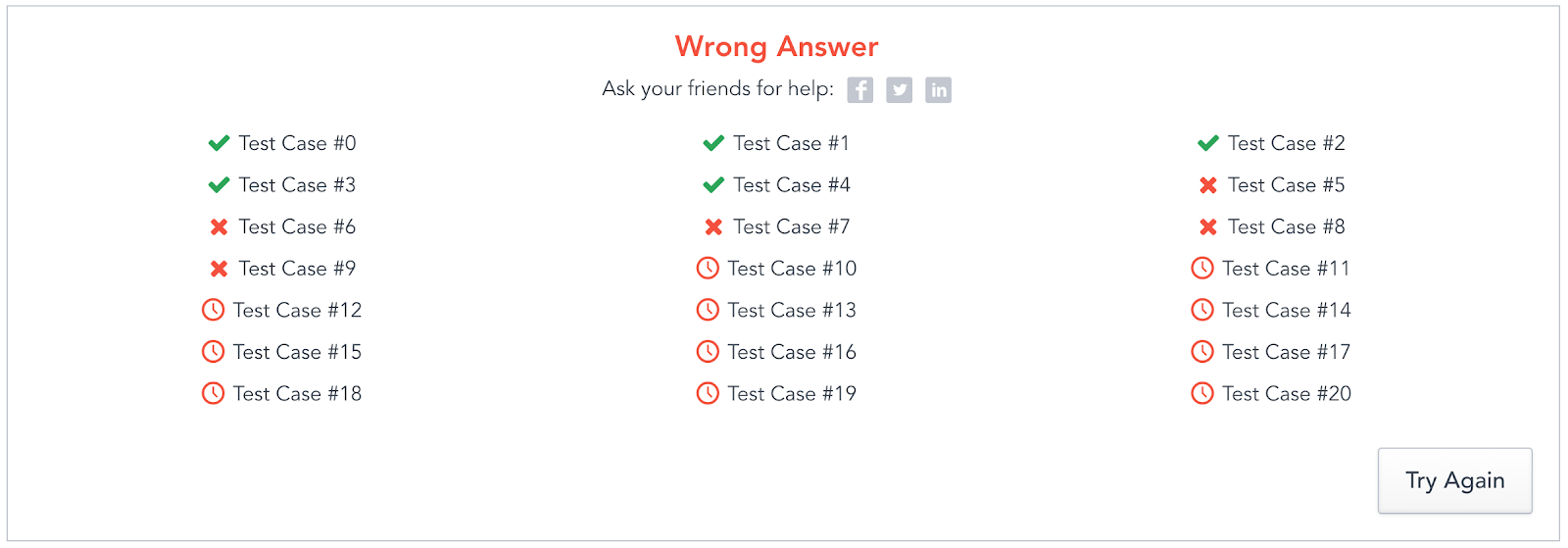
But unfortunately the world hates me, as I most likely have bugs in the implementation I don’t feel like debugging.
Post Mortem
I come back to this problem a few times a year, and every time, I am stumped. I’ve tried fixing my above implementations, caching different items, but nothing seems to work.
Let me know if you have any ideas or solutions in the comments; I’d love to get this two year old problem solved.