Data Pipelines
What’s new?
I started my new job at Google in November of 2021. For my first project on the team, I was put on a big data pipeline implementation, of which I had no experience. It was super fun but really intense for me to figure out everything from nothing, including:
- A new coding language (Java)
- A new version control
- A new code review tool
- A new web-based text editor??
- A new build tool
- A new team codebase
- A new testing system
- A new packaging system
- A new database
- A new Object Relational Mapping (ORM)
- A new programming concept (MapReduce)
- A new library to utilize said programming concept
- A new way of deploying services
- A new way of monitoring these services (x3)
Now that it’s kind of the home stretch, I thought I’d jot down the tl;dr of the project without getting into specifics. I’m also really really bored of reading bland technical documentation, so I thought I’d spice up this post a little.
Data Pipelines
What is MapReduce?
Instead of a big chonk machine doing all the work of a 25 year old’s horribly written spaghetti code, MapReduce splits up the work so that even the smol fries can perform isolated pieces of work. It’s kind of like a boss breaking up work tasks for his or her team. In the end, the output is combined to form a some feature or deliverable.
Stretching the analogy, a boss will divide the work up to give to the employees. But the boss’s work also just a piece of an organization’s bigger, more complex goal. Similarly, one instance of MapReduce-ing one computation on one dataset will probably not accomplish a data pipeline’s larger goal. There are likely many datasets that have to be MapReduced and dependencies between them.
So let’s just go one level up then. Now we have many computations (teams), with many machines (employees) each working on a small piece of each computation. However, each computation might have inputs that are the outputs of other computations. For example and for obvious reasons, Team #420 cannot start without Team #69 and #350 completing their work.
The geek who is reading this will probably think “Aha! A dependency graph!” Well, you’re right. We can model computations in a dependency graph. What do you want, a cookie?

A Data Pipeline?
With the dependency graph, we can effectively model a data pipeline that does more complex operations than any one node/team is able to. Hopefully, this will give us a fast computational data pipeline. To give you a reference point, it’s somewhere between a snake and a mongoose. And a panther.
Google’s Flume Library
Not to be confused with Apache Flume, Google’s (proprietary) Flume library is a pretty neat way to define these dependencies. Each MapReduce job’s result is represented as an output called a PCollection that defers and splits execution across other machines. The user starts with defining the data-parallel operations, and programmatically links the outputs with the inputs of other operations. Under the hood, Flume will build a dependency graph of inputs to outputs.
Within each node in the dependecy graph, Flume coordinates the actual work in the operation across many machines - the MapReduce part.
With this massively abstracted library, one can write pretty simple procedural code. For example you can probably write the following in C++/Java syntax without much change, and have Flume just do it for you. This kind of library is perfect for lazy programmers like me.
PCollection<OutputType> outputA = readDatabase(table A)
PCollection<OutputType> outputB = readDatabase(table B)
PCollection<OutputType> outputC = readDatabase(table C)
PCollection<OutputType> outputD = expensiveOperation(A, B)
PCollection<OutputType> outputE = expensiveOperation(B, C)
PCollection<OutputType> outputF = expensiveOperation(D, E)
writeToDatabase(F) // A very expensive call
Flume will generate a graph that looks like
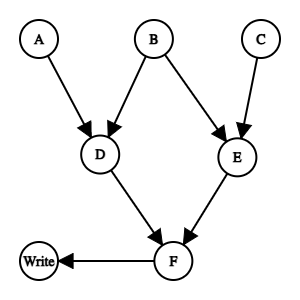
With this graph, we can pretty easily parallelize see the nodes with no dependencies and run our compute resources on them.
Some things and notes
-
If you might have noticed, the code as listed above does not actually immediately perform the work.
readDatabase()will not actually read the database just yet - Flume will defer the execution until it generates the graph. When the graph is generated from the programmer’s shit code, it can perform optimizations on the whole graph, like fusing operations that are able to belong together. -
The final, terminal step in the process is called a
Sink. This operation usually is one of persisting data to a database, writing to a text file, a log file, or some other data container.
Tuning Database Writes - The Story
Without tuning, performance of MapReduce jobs can be really slow. While sometimes you just can’t speed up an expensive CPU operations, there are certain adjustments you can make to databases, as writes can be bottlenecking.
In the project I’m working on, I have to process and persist more than 30 billion mutations to a database on the first run - more than 10TB of total data. This data pipeline will run every day.
For the first run, I took a naive approach of “just write to the db like normal human being” - that is, group the mutations in a single mutation pool, and do the write-to-db API call. Unsurprisingly, the job stalled. Even with over 4000 threads of parallelism, it spent 19 hours to barely write 9-10% of the mutations. As it was supposed to run regularly, this was unacceptable.
I slowly rip my hair out in frustration for this terrible failure, but there’s no time to wallow. A solution must be found.
“OK Taylor”, I calm myself down to think…
Speed Limit: 1,000,000
For the next genius Taylor idea, I tune the sink throttler up to a whopping 1 million commits per second in a single mutation pool, effectively hosing my own team’s database. I hope it’s not perceived as a DOS attack, but who knows. A MapReduce job with no throttler sounds exactly like a DDOS attack.
But… as expected, very quickly my team’s oncall gets paged for my insane resource usage, way above production quota. No complaints from any users though, whew. It did run faster, but compute quota is a thing.
Welp, a good attempt but no cigar. Vertical scaling can only get you so far.
Dividing Up The Mutations
Because the naive database sink cannot specify groups of transactions, maybe I can split up these transactions into groups and separately write to the DB, kind of making my own parallelism. This proved hard to even think about, how do I sample my PCollection correctly? Is sampling costly? Should it be random?
One more thing to keep in mind is that the write cost to the database is also affected by the number of RPCs made. Every time a database transaction occurs, there is a non-insignificant cost associated - the atomicity of a transaction requires locking, writing, and network latency.
Sharding and Grouping
How can we do better than just randomly sampling and writing? Time to get my thinking cap on. I put on my Noogler hat and then another hat on top of that. Two thinking caps, now we’re talking - they should do the trick. I furrow my brow, curl my toes, and bite my lip - a classic thinking position. “What’s something we know about databases?”

Well, databases are typically sharded, and after some research I find out that this one in particular is sharded by rows. For each shard of data - just a group of rows - there is a Split Point where the one shard ends and another begins.
We can query for the these Split Points in the table, and then work backwards to effectively range shard the mutations into their own mutation pools. The approach is similar to dividing up the mutations, but in locality-aware way. In this approach, mutations on the same shard will persist faster, and therefore theoretically speed up writes.
These split points aren’t static because the data isn’t static - the split points will change when keys are added. Incremental updates of split points to existing databases are also important. When splitting, we must make sure that a shard is statistically not more accessed than another. Splitting accurately can massively improve write speed, but it’s tough to give an estimate because performance can vary with the type of db used and its implementation.
Unknowns and Tradeoffs
But splitting/sharding a database doesn’t solve writing singehandedly - there are many more unknowns: Should each shard get its own mutation pool? How big should a mutation pool be? How many pools should there be?
The number of mutations should be large enough that writing to database is efficient, and so that we don’t have millions of transactions. As noted previously, the more transactions you have, the more costly the whole operation will be. On the other hand, we can’t make each transaction so large that the data is split across so many shards that it runs into long-tail issues - a problem where some shards have stragglers that take a long time to be persisted. How can we find the right balance?

Liquid Sharding
The Taylor definition of liquid sharding means “if slow, throw more parallelism at it”.
More formally, it’s dynamic runtime optimization that allows Flume to minimize the above mentioned stragglers by splitting them into pieces that can be processed in parallel. It continually divides tasks and lets the system rebalance its workload and increase parallelism.
This runtime optimization will help in batch mutations for sure, or so I thought. Fortunately for me, liquid sharding is built-in with Flume and we should get it for free. Unfortunately for me, I don’t think liquid sharding is smart enough to break down a large straggler into smaller ones, since we’ve already kind of split the data being written in a previous step.
A workaround can be to manually break large chunks of data even further in each MutationPool to something more manageable. By this, I mean literally limiting the byte size of each chunk, say in the hundreds of MB vs a pool that may contain up to 10GB. But, a normal mutation pool does not support that kind of functionality - which means an implementation of a ShardedMutationPool needs to be made. Upon further research, it seems that we can achieve a similar behavior with a Stream of Mutations, and adding extra data along with the stream that will guide the break points.
At the end of the day, the sharding concept worked.
I started the implementation, buta new Spanner version was released just a week after that had this exact feature!
- The naive method would have taken 200 hours for just the database writes, assuming the slow mutation pool scales linearly. Not great for a job that must run every 24 hours.
- The group-by-split-point method took about 10 hours, which includes writing to the database and the work for pre-write computations. While still not great, it’s an order of magnitude faster! Nice.
Some observations
I realize that the technique used to optimize writes is actually really similar to MapReduce, except simple data computation is natively supported while terminal/write operations require some tweaking.
In MapReduce, we break down a big task into parallelizable smaller computations. The same technique is being applied with db writes - we keep splitting the big MutationPool dump down into manageable parts: first by locality through sharding and analyzing split points, and the second through limiting the size of the flume group to be processed.
For the lols, and credits.
Obviously, a lot of the writing/storytelling is just for the memes. While the core technical ideas are correct, I did not one day think “1 million commits!” single handedly and then fix a complex performance issue like this. Thankfully I had an amazingly competent TL and awesome internal docs to help me along the way.